

Machine Learning
El aprendizaje automático, también conocido como machine learning en inglés, es una rama de la inteligencia artificial que se centra en el desarrollo de algoritmos y modelos que permiten a las computadoras aprender y mejorar su rendimiento en tareas específicas a través de la experiencia y la exposición a datos. En lugar de ser programadas explícitamente para llevar a cabo una tarea en particular, las máquinas aprenden a partir de ejemplos y patrones en los datos.
En esencia, el machine learning busca crear modelos matemáticos y estadísticos que puedan identificar patrones, relaciones y regularidades en los datos para hacer predicciones, tomar decisiones o realizar tareas específicas. Estos modelos se entrenan utilizando conjuntos de datos de entrenamiento que contienen ejemplos etiquetados o información de entrada y salida correspondiente. A medida que el modelo se expone a más datos, ajusta sus parámetros internos y mejora su capacidad para realizar tareas con mayor precisión.

Hay diferentes tipos de aprendizaje automático, que incluyen:
1. Aprendizaje supervisado: Se proporciona al modelo un conjunto de datos de entrenamiento que contiene ejemplos etiquetados, es decir, se conoce la relación entre las entradas y las salidas esperadas. El modelo aprende a predecir las salidas correctas basándose en las entradas dadas.
2. Aprendizaje no supervisado: En este enfoque, el modelo se expone a datos sin etiquetas y busca identificar patrones o estructuras intrínsecas en los datos, como agrupaciones (clustering) o reducción de dimensionalidad.
3. Aprendizaje por refuerzo: El modelo aprende a través de la interacción con un entorno. Recibe retroalimentación en forma de recompensas o penalizaciones según las acciones que toma, lo que le permite aprender a tomar decisiones que maximicen las recompensas a lo largo del tiempo.
El aprendizaje automático tiene aplicaciones en una amplia variedad de campos, como reconocimiento de voz, visión por computadora, procesamiento de lenguaje natural, medicina, finanzas, marketing y muchas otras áreas donde los patrones y las relaciones en los datos pueden proporcionar información valiosa para la toma de decisiones y la automatización de tareas.
Un ejemplo relacionado con el machine learning en la vida cotidiana es el algoritmo de recomendación de YouTube el cual podría estar basado en la predicción de videos que un usuario podría disfrutar según su historial de reproducción y comportamiento de navegación. Cabe mencionar que los detalles exactos del algoritmo de YouTube son confidenciales y no están disponibles públicamente.

Haciendo uso de Python, podemos presentar un ejemplo simplificado de cómo podrías crear un sistema de recomendación básico utilizando técnicas de aprendizaje automático.
Supongamos que tenemos un conjunto de datos con información sobre los videos que un usuario ha visto anteriormente y queremos predecir qué otro video podría interesarle. Utilizaremos una técnica simple llamada filtrado colaborativo basado en usuarios para este ejemplo. Esto significa que haremos recomendaciones basadas en los patrones de comportamiento similares entre usuarios.
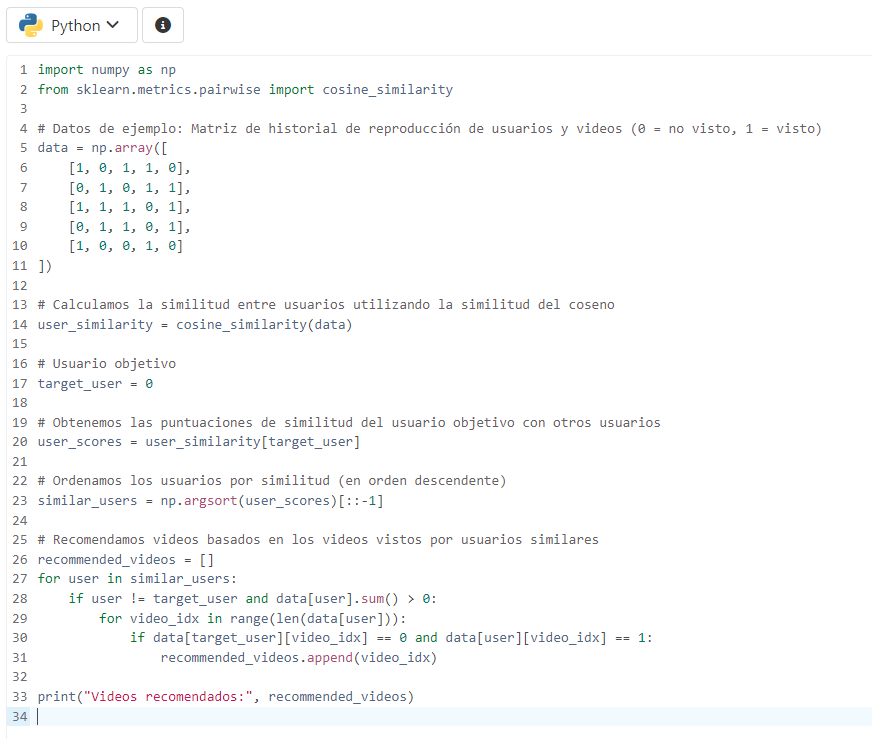
Este es un ejemplo muy simplificado y no representa con precisión el sofisticado algoritmo de recomendación de YouTube. Los sistemas reales utilizan datos más complejos, como características de video, comportamiento del usuario y otros factores para hacer recomendaciones precisas. Además, consideraciones éticas y de privacidad son fundamentales al desarrollar sistemas de recomendación.